
"Deep learning allows computational models that are composed of multiple processing layers to learn representations of data with multiple levels of abstraction.
So, how do I start learning DL and Deep neural networks:
Let us have a clear understanding of :
- What neural networks, deep learning Networks and how they work?
- Basic optimization theory, optimization techniques, gradients and loss functions
- Good understand of Python
The most popular techniques are:
- Multilayer Perceptron Networks.
- Convolutional Neural Networks.
- Long Short-Term Memory Recurrent Neural Networks.
Neural networks process information in a similar way the human brain does. The network is composed of a large number of highly interconnected processing elements (neurones) working in parallel to solve a specific problem. Neural networks learn by example. They cannot be programmed to perform a specific task.
Neural architecture search
Is the process of automating the design of neural networks. Neural architecture search is good for problems that require the discovering of new architectures. Ato-sklearn frees a machine learning user from algorithm selection and hyperparameter tuning.
Transfer learning
Transfer learning is a technique where one uses pre-trained models to transfer what its learned when applying the model to a similar new dataset. This enables to obtain high accuracies while using less computation time and power. Transfer learning works best for problems where the datasets are similar to the ones used in pre-training models.
Auto-sklearn performs the best on the classification datasets

Let us also look at some of the Python Machine Learning Open Source Projects.
- TensorFlow (TF). Developed by Google, it is designed to facilitate research in machine learning, and to make it quick and easy to transition from research prototype to production system.
- Scikit-learn. A simple tools for data mining and data analysis, built on NumPy, SciPy, and matplotlib
- PyTorch. An Open source Machine Learning library for python. In TensorFlow, graph is defined statically before running a model whereas in PyTorch, graph construction is dynamic and nodes can be defined, changed and executed on the go. It is developed by Facebook's Artificial-Intelligence research group.
- Keras. A high-level neural networks API, written in Python and capable of running on top of TensorFlow. Keras is a streamlined API that makes coding DL systems that much easier
- PyBrain is a modular Machine Learning Library for Python. Its goal is to offer flexible, easy-to-use yet still powerful algorithms for Machine Learning Tasks and a variety of predefined environments to test and compare your algorithms.
- Microsoft Cognitive Toolkit is an open-source deep learning framework. It performs efficient convolution neural networks and training for image, speech, and text-based data.
RNN
In traditional neural networks, all the inputs and outputs are independent of each other. Recurrent Neural Network(RNN) the output from previous step are fed as input to the current step. RNN is Hidden state, which remembers some information about a sequence.
RNN converts the independent activations into dependent activations by providing the same weights and biases to all the layers, thus reducing the complexity of increasing parameters and memorizing each previous outputs by giving each output as input to the next hidden layer.
Hence these three layers can be joined together such that the weights and bias of all the hidden layers is the same, into a single recurrent layer.
Advantages of Recurrent Neural Network
An RNN remembers each and every information through time. It is useful in time series prediction only because of the feature to remember previous inputs as well. This is called Long Short Term Memory.
Recurrent neural network are even used with convolutional layers to extend the effective pixel neighborhood.
Disadvantages of Recurrent Neural Network
Gradient vanishing and exploding problems.
Training an RNN is a very difficult task.
It cannot process very long sequences if using tanh or relu as an activation function.
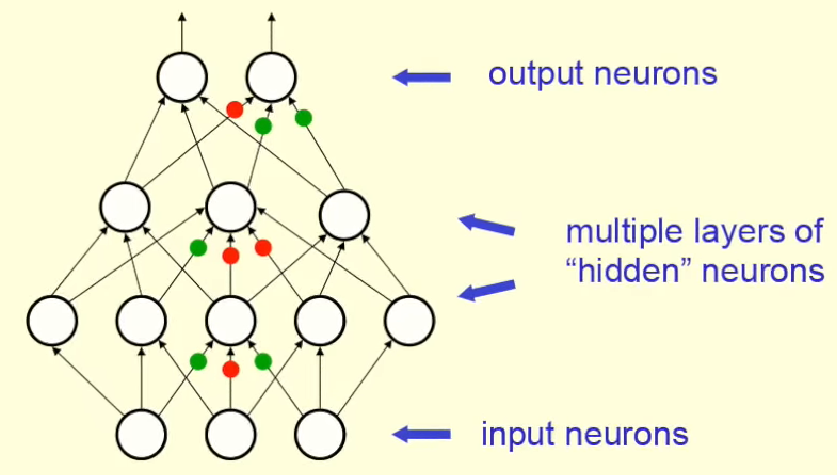
Recurrent neural networks (Recurrent connections between the hidden neurons)
Input Layer : Accepts input features and passes on the information(features) to the hidden layer.
Hidden Layer : These Nodes are the part of the abstraction provided by any neural network. Hidden layer performs all sort of computation on the features entered through the input layer and transfer the result to the output layer.
Output Layer :- This layer outputs the information learned by the network.
Activation function decides, whether a neuron should be activated or not by calculating weighted sum and adding bias with it. The purpose of the activation function is to introduce non-linearity into the output of a neuron.
ReLU (Rectified Linear Unit) Activation Function. The ReLU is the most used activation function in the world right now.
The rectified linear activation function is a simple calculation that returns the value provided as input directly, or the value 0.0 if the input is 0.0 or less.
Sigmoid Neuron - Logistic regression
Perceptron model can not be applied to non-linear data. The function is harsh at tthe boundry
The sigmoid function is a special case of the more general logistic function, and it essentially squashes input to be between zero and one. Its derivative has advantageous properties, which partially explains its widespread use as an activation function in neural networks.
Sigmoid model provides a smoother function and not optimized to separate outputs efficiently.

PyTorch is an open source machine learning library, used for applications such as computer vision and natural language processing.
Tensors
Tensors are similar to NumPy’s ndarrays, with the addition being that Tensors can also be used on a GPU to accelerate computing.
#py1.py
from __future__ import print_function
import torch
x = torch.empty(3, 4)
print(x)
output
tensor([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]])
#py2.py
from __future__ import print_function
import torch
result = torch.empty(5, 3)
x = torch.rand(5, 3)
y = torch.rand(5, 3)
print(x + y)
torch.add(x, y, out=result)
print(result)
output
tensor([[0.3514, 0.5698, 0.4444],
[1.2607, 1.0404, 1.7043],
[1.0464, 0.9752, 0.7726],
[0.3635, 1.4963, 1.3634],
[0.8632, 0.8090, 1.4006]])
tensor([[0.3514, 0.5698, 0.4444],
[1.2607, 1.0404, 1.7043],
[1.0464, 0.9752, 0.7726],
[0.3635, 1.4963, 1.3634],
[0.8632, 0.8090, 1.4006]])
#py3.py
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 1 input image channel, 6 output channels, 3x3 square convolution
# kernel
self.conv1 = nn.Conv2d(1, 6, 3)
self.conv2 = nn.Conv2d(6, 16, 3)
# an affine operation: y = Wx + b
self.fc1 = nn.Linear(16 * 6 * 6, 120) # 6*6 from image dimension
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# Max pooling over a (2, 2) window
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# If the size is a square you can only specify a single number
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # all dimensions except the batch dimension
num_features = 1
for s in size:
num_features *= s
return num_features
net = Net()
print(net)
output
Net(
(conv1): Conv2d(1, 6, kernel_size=(3, 3), stride=(1, 1))
(conv2): Conv2d(6, 16, kernel_size=(3, 3), stride=(1, 1))
(fc1): Linear(in_features=576, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=10, bias=True)
)
Microsoft and Tesla are using PyTorch for adding Artificial Intelligence capabilities. While Tesla has integrated it for autopilot in the car, Microsoft has been using it for internal developments and have also brought support on Azure.
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 1 input image channel, 6 output channels, 3x3 square convolution
# kernel
self.conv1 = nn.Conv2d(1, 6, 3)
self.conv2 = nn.Conv2d(6, 16, 3)
# an affine operation: y = Wx + b
self.fc1 = nn.Linear(16 * 6 * 6, 120) # 6*6 from image dimension
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# Max pooling over a (2, 2) window
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# If the size is a square you can only specify a single number
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # all dimensions except the batch dimension
num_features = 1
for s in size:
num_features *= s
return num_features
net = Net()
print(net)
output
Net(
(conv1): Conv2d(1, 6, kernel_size=(3, 3), stride=(1, 1))
(conv2): Conv2d(6, 16, kernel_size=(3, 3), stride=(1, 1))
(fc1): Linear(in_features=576, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=10, bias=True)
)
Microsoft and Tesla are using PyTorch for adding Artificial Intelligence capabilities. While Tesla has integrated it for autopilot in the car, Microsoft has been using it for internal developments and have also brought support on Azure.
Sigmoid function is used in artificial neural networks to determine the relationships between biological and artificial neural networks.
Sigmoid functions can be used as activation functions in neural nets. The Sigmoid function squashes an input, x, between two numbers — 0 and 1. While Sigmoid isn’t the only activation function used in deep learning, it was one of the first to gain widespread use in the early days of neural networks.
#
# Sigmoid function
# sigmoid1.py
# 3rd Nov 2018
# Ver 1.0
#
import numpy as np
import matplotlib.pyplot as plt
def sigmoid (x,w,b):
return 1/(1+np.exp(-(w*x+b)))
w = 1 # @param{type:"slider",min:-3,max:4,step.01}
b = -1.1 # @param{type:"slider",min:-2,max:5,step.01}
X = np.linspace(-10,10,100) # numpy array
Y = sigmoid(X,w,b)
plt.plot(X,Y)
plt.show()
Output

Deep learning is part of machine learning that is inspired by the structure and function of the brain.
'TensorFlow' is the second machine learning and most popular DL framework by Google for designing, building and training deep learning models as on today. TensorFlow can train a network with millions of parameters on a training set composed of billions of instances with millions of features each.
Its basic principle is simple; first define in Python a graph of computations to perform and then TensorFlow takes that graph and runs it efficiently.
Example-2
# Plotting Sigmoid Function
# Sigmoid Neuron
#
# sigmoid2.py
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits import mplot3d
import matplotlib.colors
import pandas as pd
def sigmoid_2d(x1, x2, w1, w2, b):
return 1/(1 + np.exp(-(w1*x1 + w2*x2 + b)))
sigmoid_2d(1, 0, 0.5, 0, 0)
X1 = np.linspace(-10, 10, 100)
X2 = np.linspace(-10, 10, 100)
XX1, XX2 = np.meshgrid(X1, X2)
print(X1.shape, X2.shape, XX1.shape, XX2.shape)
w1 = 2
w2 = -0.5
b = 0
Y = sigmoid_2d(XX1, XX2, w1, w2, b)
my_cmap = matplotlib.colors.LinearSegmentedColormap.from_list("", ["red","yellow","green"])
plt.contourf(XX1, XX2, Y, cmap = my_cmap, alpha = 0.6)
plt.show()
Output

Softmax and Sigmoid
Softmax: Used for the multi-classification task.
Sigmoid: Used for the binary classification task.
Softmax function calculates the probabilities distribution of the event over ‘n’ different events. Softmax will calculate the probabilities of each target class over all possible target classes. The calculated probabilities will be helpful for determining the target class for the given inputs.
If the softmax function used for multi-classification model it returns the probabilities of each class and the target class will have the high probability.
# softmax1.py
import numpy as np
import matplotlib.pyplot as plt
def softmax(inputs):
"""
Calculate the softmax for the give inputs (array)
:param inputs:
:return:
"""
return np.exp(inputs) / float(sum(np.exp(inputs)))
def line_graph(x, y, x_title, y_title):
"""
Draw line graph with x and y values
:param x:
:param y:
:param x_title:
:param y_title:
:return:
"""
plt.plot(x, y)
plt.xlabel(x_title)
plt.ylabel(y_title)
plt.show()
graph_x = range(0, 21)
graph_y = softmax(graph_x)
print ("Graph X readings: {}".format(graph_x))
print ("Graph Y readings: {}".format(graph_y))
line_graph(graph_x, graph_y, "Inputs", "Softmax Scores")

Sigmoid
# sg2.py
#
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(inputs):
"""
Calculate the sigmoid for the give inputs (array)
:param inputs:
:return:
"""
sigmoid_scores = [1 / float(1 + np.exp(- x)) for x in inputs]
return sigmoid_scores
def line_graph(x, y, x_title, y_title):
"""
Draw line graph with x and y values
:param x:
:param y:
:param x_title:
:param y_title:
:return:
"""
plt.plot(x, y)
plt.xlabel(x_title)
plt.ylabel(y_title)
plt.show()
graph_x = range(0, 21)
graph_y = sigmoid(graph_x)
print ("Graph X readings: {}",format(graph_x))
print ("Graph Y readings: {}",format(graph_y))
line_graph(graph_x, graph_y, "Inputs", "Sigmoid Scores")

Non-linear Data
#
# ffn1.py
# Generate data that is not linearly separable
# Train with SN and see performance
#
# Feedforward network - Deeper networks
# SigmoidNeuron - non linear data - Multi class clasification
#
import numpy as np
import tqdm
import matplotlib.pyplot as plt
import matplotlib.colors
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, mean_squared_error
from tqdm import tqdm_notebook
from sklearn.preprocessing import OneHotEncoder
from sklearn.datasets import make_blobs
class SigmoidNeuron:
def __init__(self):
self.w = None
self.b = None
def perceptron(self, x):
return np.dot(x, self.w.T) + self.b
def sigmoid(self, x):
return 1.0/(1.0 + np.exp(-x))
def grad_w_mse(self, x, y):
y_pred = self.sigmoid(self.perceptron(x))
return (y_pred - y) * y_pred * (1 - y_pred) * x # forward pass
def grad_b_mse(self, x, y):
y_pred = self.sigmoid(self.perceptron(x))
return (y_pred - y) * y_pred * (1 - y_pred)
# gradient computation
def grad_w_ce(self, x, y):
y_pred = self.sigmoid(self.perceptron(x))
if y == 0:
return y_pred * x
elif y == 1:
return -1 * (1 - y_pred) * x
else:
raise ValueError("y should be 0 or 1")
def grad_b_ce(self, x, y):
y_pred = self.sigmoid(self.perceptron(x))
if y == 0:
return y_pred
elif y == 1:
return -1 * (1 - y_pred)
else:
raise ValueError("y should be 0 or 1")
def fit(self, X, Y, epochs=1, learning_rate=1, initialise=True, loss_fn="mse", display_loss=False):
# initialise w, b
if initialise:
self.w = np.random.randn(1, X.shape[1])
self.b = 0
if display_loss:
loss = {}
for i in tqdm_notebook(range(epochs), total=epochs, unit="epoch"):
dw = 0
db = 0
for x, y in zip(X, Y):
if loss_fn == "mse":
dw += self.grad_w_mse(x, y)
db += self.grad_b_mse(x, y)
elif loss_fn == "ce":
dw += self.grad_w_ce(x, y)
db += self.grad_b_ce(x, y)
m = X.shape[1]
self.w -= learning_rate * dw/m
self.b -= learning_rate * db/m
if display_loss:
Y_pred = self.sigmoid(self.perceptron(X))
if loss_fn == "mse":
loss[i] = mean_squared_error(Y, Y_pred)
elif loss_fn == "ce":
loss[i] = log_loss(Y, Y_pred)
if display_loss:
plt.plot(loss.values())
plt.xlabel('Epochs')
if loss_fn == "mse":
plt.ylabel('Mean Squared Error')
elif loss_fn == "ce":
plt.ylabel('Log Loss')
plt.show()
def predict(self, X):
Y_pred = []
for x in X:
y_pred = self.sigmoid(self.perceptron(x))
Y_pred.append(y_pred)
return np.array(Y_pred)
my_cmap = matplotlib.colors.LinearSegmentedColormap.from_list("", ["blue","orange","green"])
# blue small number, green larger number
np.random.seed(0)
#Generate data
# 2 scalar inputs, 4 blocks, 10000 samples
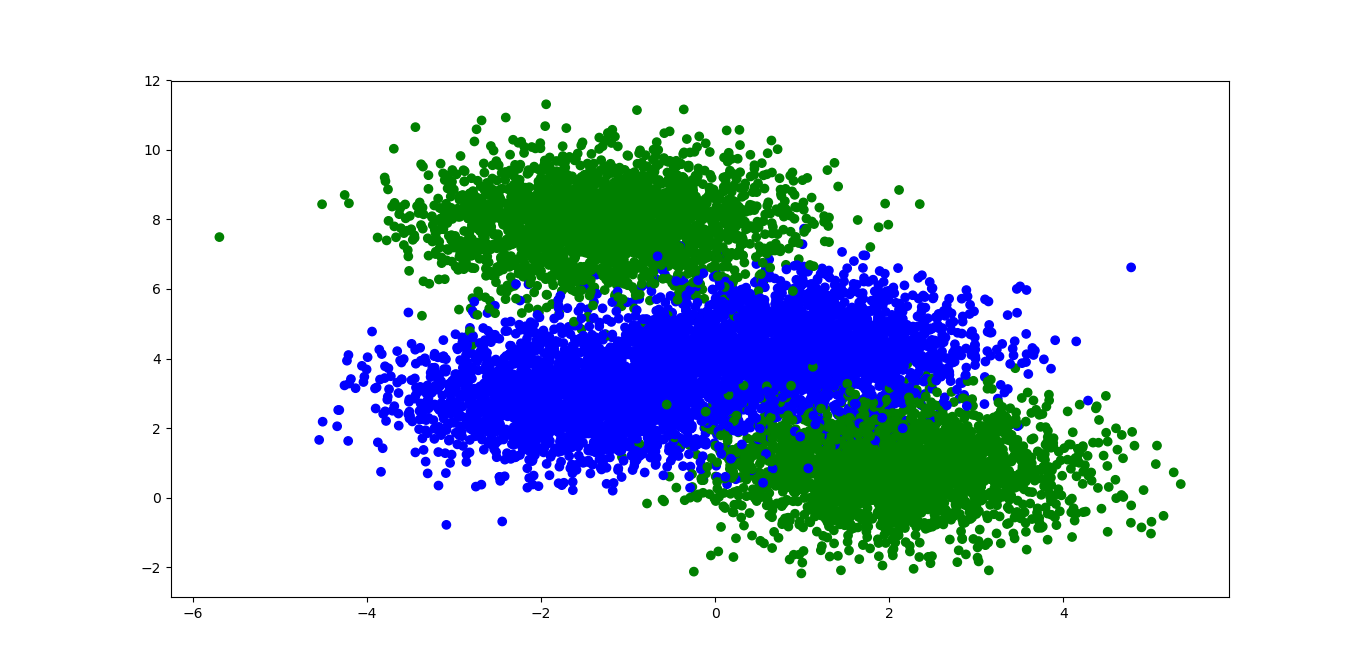
data, labels = make_blobs(n_samples=10000, centers=4, n_features=2, random_state=0)
print(data.shape, labels.shape) # (1000, 2) (1000,)
plt.scatter(data[:,0], data[:,1], c=labels, cmap=my_cmap)
plt.show()
labels_orig = labels
labels = np.mod(labels_orig, 2)
# combine blocks and show only 2 blocks - Binary clacification
# decision boundry is not linear
plt.scatter(data[:,0], data[:,1], c=labels, cmap=my_cmap)
plt.show()
# Split train and test data
X_train, X_val, Y_train, Y_val = train_test_split(data, labels, stratify=labels, random_state=0)
print(X_train.shape, X_val.shape) # (750, 2) (250, 2)
Output

# acti1.py
# Activation function
# RELU
#
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers.core import Dense, Activation
from keras.utils import np_utils
(X_train, Y_train), (X_test, Y_test) = mnist.load_data()
X_train = X_train.reshape(60000, 784)
X_test = X_test.reshape(10000, 784)
X_train = X_train.astype('float32') / 255
X_test = X_test.astype('float32') / 255
Y_train = np_utils.to_categorical(Y_train, 10)
Y_test = np_utils.to_categorical(Y_test, 10)
batch_size = 200
epochs = 20
model = Sequential()
model.add(Dense(100, input_dim=784))
model.add(Activation('relu'))
model.add(Dense(10))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', metrics=['accuracy'], optimizer='sgd')
model.fit(X_train, Y_train, batch_size=batch_size, epochs=epochs, verbose=1)
score = model.evaluate(X_test, Y_test, verbose=1)
print ("Activation function : RELU")
print('Test accuracy:', score[1])
Activation function : RELU Test accuracy: 0.926
Backpropagation
Backpropagation is a supervised learning algorithm, for training Multi-layer Perceptrons (Artificial Neural Networks).
* Calculate the error – How far is your model output from the actual output.
* Minimum Error – Check whether the error is minimized or not.
* Update the parameters – If the error is huge then, update the parameters (weights and biases). After that again check the error. Repeat the process until the error becomes minimum.
Backpropagation algorithm looks for the minimum value of the error function in weight, using gradient descent. The weights that minimize the error function is then considered to be a solution to the learning problem.
Y_pred_train = ffsn_multi_specific.predict(X_train)
Y_pred_train = np.argmax(Y_pred_train,1)
Y_pred_val = ffsn_multi_specific.predict(X_val)
Y_pred_val = np.argmax(Y_pred_val,1)
accuracy_train = accuracy_score(Y_pred_train, Y_train)
accuracy_val = accuracy_score(Y_pred_val, Y_val)
print("Training accuracy", round(accuracy_train, 2))
print("Validation accuracy", round(accuracy_val, 2))
plt.scatter(X_train[:,0], X_train[:,1], c=Y_pred_train, cmap=my_cmap, s=15*(np.abs(np.sign(Y_pred_train-Y_train))+.1))
plt.show()
Training accuracy 0.79
Validation accuracy 0.8


Backpropagation was one of the first methods able to demonstrate that Artificial Neural Networks could learn good internal representations, i.e. their hidden layers learned features.

Vectorization Implementation in Machine Learning
As per Intel "Vectorization is the process of converting an algorithm from operating on a single value at a time to operating on a set of values at one time. Modern CPUs provide direct support for vector operations where a single instruction is applied to multiple data (SIMD)."
Vectorization dramatically improving the performance of code. To compute the sum of the values of an array. The easy way is to loop over the elements and to sequentially sum them. This process is slow and tends to get slower with large amounts of data.
With vectorization these operations can be seen as matrix operations which are often more efficient.
#Testing vectorisation
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.colors
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, mean_squared_error, log_loss
from tqdm import tqdm_notebook
import seaborn as sns
import imageio
import time
from IPython.display import HTML
from sklearn.preprocessing import OneHotEncoder
from sklearn.datasets import make_blobs
my_cmap = matplotlib.colors.LinearSegmentedColormap.from_list("", ["red","yellow","green"])
np.random.seed(0)
N = 100
M = 200
a = np.random.randn(N, M)
b = np.random.randn(N, M)
c = np.zeros((N, M))
%%time
for i in range(N):
for j in range(M):
c[i, j] = a[i, j] + b[i, j]
Output
CPU times: user 15.7 ms, sys: 730 µs, total: 16.5 ms
Wall time: 21.4 ms
%%time
c = a + b
Output
CPU times: user 360 µs, sys: 29 µs, total: 389 µs
Wall time: 277 µs
Example-3
# tensorflow-1
import tensorflow as tf
# Initialize two constants
x1 = tf.constant([1,2,3,4])
x2 = tf.constant([5,6,7,8])
# Multiply
result = tf.multiply(x1, x2)
# Print the result
print(result)
Output
Tensor("Mul:0", shape=(4,), dtype=int32)
Example-4
# tensorflow-2
import tensorflow as tf
# Initialize two constants
x1 = tf.constant([1,2,3,4])
x2 = tf.constant([5,6,7,8])
# Multiply
result = tf.multiply(x1, x2)
# Intialize the Session
sess = tf.Session()
# Print the result
print(sess.run(result))
# Close the session
sess.close()
Output
[ 5 12 21 32]
Linear regression using keras
# linear regression using keras
import keras
from keras.models import Sequential
from keras.layers import Dense, Activation
import numpy as np
import matplotlib.pyplot as plt
x = data = np.linspace(1,2,200)
y = x*4 + np.random.randn(*x.shape) * 0.3
print (x)
print (y)
model = Sequential()
model.add(Dense(1, input_dim=1, activation='linear'))
# optimizer used is sgd - Stochastic gradient descent refers to calculating the derivative from each training data instance and calculating the update immediately.
# loss function used is mse - MSE is the sum of squared distances between our target variable and predicted values.
# A metric is a function that is used to judge the performance of.
# A metric function is similar to a loss function, except that the results from evaluating a metric are not used when training the model.
# Can use any of the loss functions as a metric function.
model.compile(optimizer='sgd', loss='mse', metrics=['mse'])
weights = model.layers[0].get_weights()
w_init = weights[0][0][0]
b_init = weights[1][0]
print('Linear regression model is initialized with weights w: %.2f, b: %.2f' % (w_init, b_init))
model.fit(x,y, batch_size=1, epochs=30, shuffle=False)
weights = model.layers[0].get_weights()
w_final = weights[0][0][0]
b_final = weights[1][0]
print('Linear regression model is trained to have weight w: %.2f, b: %.2f' % (w_final, b_final))
predict = model.predict(data)
plt.plot(data, predict, 'b', data , y, 'k.')
plt.show()

Google Colaboratory is a research tool for machine learning education and research. It’s a Jupyter notebook environment that requires no setup to use
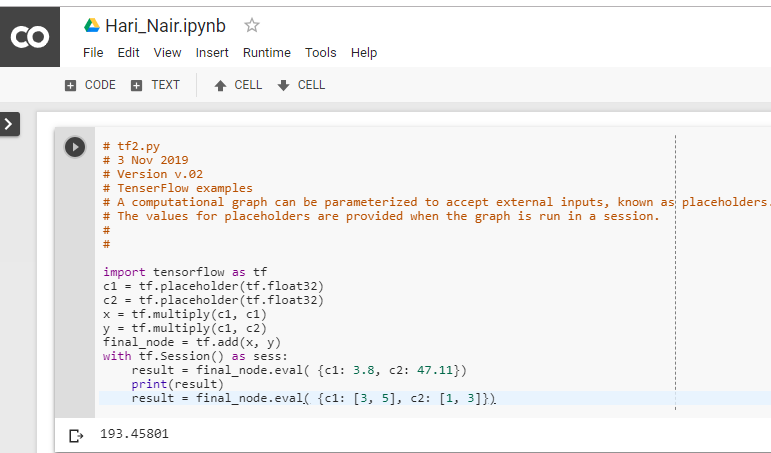
Example-5
# tf2.py
# 3 Nov 2019
# Version v.02
# TenserFlow examples
# A computational graph can be parameterized to accept external inputs, known as placeholders.
# The values for placeholders are provided when the graph is run in a session.
#
#
import tensorflow as tf
c1 = tf.placeholder(tf.float32)
c2 = tf.placeholder(tf.float32)
x = tf.multiply(c1, c1)
y = tf.multiply(c1, c2)
final_node = tf.add(x, y)
with tf.Session() as sess:
result = final_node.eval( {c1: 3.8, c2: 47.11})
print(result)
result = final_node.eval( {c1: [3, 5], c2: [1, 3]})
print(result)
Output
193.45801
Let us now create Class for Sigmoid neuron
# Class for Sigmoid neuron
# Ver 1.1
#
class SigmoidNeuron:
def __init__(self):
self.w = None
self.b = None
def perceptron(self, x): # forward pass perceptron
return np.dot(x, self.w.T) + self.b
def sigmoid(self, x):
return 1.0/(1.0 + np.exp(-x))
# compute fit
def grad_w(self, x, y): # compute gradients
y_pred = self.sigmoid(self.perceptron(x))
return (y_pred - y) * y_pred * (1 - y_pred) * x
def grad_b(self, x, y): # compute gradient b
y_pred = self.sigmoid(self.perceptron(x))
return (y_pred - y) * y_pred * (1 - y_pred) # predicted value of y
def fit(self, X, Y, epochs=1, learning_rate=1, initialise=True): # learning rate
# initialise w, b # one row and several rows
if initialise:
self.w = np.random.randn(1, X.shape[1])
self.b = 0 # scalar
for i in range(epochs): # go through the data and compute gradient each time
dw = 0
db = 0
for x, y in zip(X, Y): # go though the inputs
dw += self.grad_w(x, y) # computeand accumulate
db += self.grad_b(x, y) # update values
self.w -= learning_rate * dw
self.b -= learning_rate * db
Gradient Descent and Linear Regression
Gradient descent is an algorithm that minimizes functions. Given a function defined by a set of parameters, gradient descent starts with an initial set of parameter values and iteratively moves toward a set of parameter values that minimize the function.
Applications includes:
Gradient descent is an algorithm that minimizes functions. Given a function defined by a set of parameters, gradient descent starts with an initial set of parameter values and iteratively moves toward a set of parameter values that minimize the function.
Tensorflow helps in the process of Acquiring data, Training models, Serving predictions and refining future results. TensorFlow allows to create Dataflow graphs that describe how Data moves through a graph or a series of processing nodes. Each node in the graph represents a mathematical operation and each connection between nodes is a multidimensional data array, or tensor. Instead of dealing with the nitty-gritty details of implementing algorithms or figuring out proper ways to hitch the output of one function to the input of another the developer can focus on the overall logic of the application. TensorFlow takes care of the details behind the scenes.
Applications includes:
- Speech recognition
- Image recognition
- Object tagging videos
- Diagnostics
- Self-driving cars
- Sentiment analysis
- Detection of flaws
- Text analysis
- Mobile image and video processing
- Drones
Neural networks can learn their weights and biases using the gradient descent algorithm. The goals is adjust each weight in the network in proportion to how much it contributes to overall error rate. If we interactively reduce each weight’s error, eventually we’ll have a series of weights the produce good predictions.


Facial expression recognition has been an active research area for several years. Images of the same person in the same facial expression can vary in brightness, background and pose. Convolutional Neural Networks achieve better accuracy with big data. However, there are no publicly available datasets with sufficient data for facial expression recognition.
Keras is a powerful easy-to-use Python library for developing and evaluating deep learning models. There are two ways to build Keras models: sequential and functional.
The sequential API allows to create models layer-by-layer but does not allow you to create models that share layers or have multiple inputs or outputs.
Functional API allows to create models that have a lot more flexibility, where layers connect to more than just the previous and next layers. Creating complex networks are possible
#
#
# Keras is a powerful easy-to-use Python library for developing and evaluating deep learning models.
# Pima Indians Diabetes Database
#
import numpy
import keras
from keras.models import Sequential
from keras.layers import Dense
import numpy
# fix random seed for reproducibility
numpy.random.seed(7)
# load dataset
dataset = numpy.loadtxt("pima-indians-diabetes.csv", delimiter=",")
# split data into input (X) and output (Y) variables
X = dataset[:,0:8]
Y = dataset[:,8]
# create model
model = Sequential()
model.add(Dense(12, input_dim=8, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# Compile model
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# Fit the model
model.fit(X, Y, epochs=150, batch_size=10)
# evaluate the model
scores = model.evaluate(X, Y)
print("\n%s: %.2f%%" % (model.metrics_names[1], scores[1]*100))
Output
Accuracy: 79.17%
With Batch size 10 and 150 epochs , accuracy is 79.17%
Once we have a good understanding of Deep learning try
CNN
Convolutional neural networks (CNN) are widely used in images recognition, images classifications Objects detections etc. Deep learning CNN models to train and test, each input image will pass it through a series of convolution layers with filters (Kernals), Pooling, fully connected layers (FC) and apply Softmax function to classify an object with probabilistic values between 0 and 1.
Convolution is the first layer to extract features from an input image. Convolution preserves the relationship between pixels by learning image features using small squares of input data. Convolution of an image with different filters can perform operations such as edge detection, blur and sharpen by applying filters. CNNs are especially tricky to train, as they add even more hyper-parameters than a standard MLP. While the usual rules of thumb for learning rates and regularization constants still apply, the following should be kept in mind when optimizing CNNs.
There are a few distinct types of Layers (e.g. CONV/FC/RELU/POOLetc.)
Each Layer accepts an input 3D volume and transforms it to an output 3D volume through a differentiable function

https://playground.tensorflow.org
Transfer Learning
A technique that reuses a model that was created by machine learning experts and that has already been trained on a large dataset. Transfer the learning of an existing model to a new dataset. When performing transfer learning we must always change the last layer of the pre-trained model so that it has the same number of classes that we have in the dataset we are working with.
Wen working with a small dataset, it is common to leverage the features learned by a model trained on a larger dataset. This is done by instantiating the pre-trained model and adding a fully connected classifier on top. The pre-trained model is "frozen" and only the weights of the classifier are updated during training. The convolutional base extracts all the features associated with each image and we train a classifier that determines, given these set of features to which class it belongs.
Fine-tuning a pre-trained model - to further improve performance, one might want to repurpose the top-level layers of the pre-trained models to the new dataset via fine-tuning. In this case, we tune our weights such that we learn highly specified and high level features specific to our dataset. This only make sense when the training dataset is large and very similar to the original dataset that the pre-trained model was trained on.
Freezing Parameters: Setting the variables of a pre-trained model to non-trainable. By freezing the parameters, we will ensure that only the variables of the last classification layer get trained, while the variables from the other layers of the pre-trained model are kept the same.
MobileNet: A state-of-the-art convolutional neural network developed by Google that uses a very efficient neural network architecture that minimizes the amount of memory and computational resources needed, while maintaining a high level of accuracy. MobileNet is ideal for mobile devices that have limited memory and computational resources.
 My next Blog on AI in Financial industry
My next Blog on AI in Financial industry